How Facial Recognition Works
In this article, we'll talk about facial recognition algorithms and how they work. We'll take a look at a generic facial recognition process and all the basic steps involved.
Face recognition has stopped being a subject of science fiction and safely transitioned to the real world, being one of the most popular applications of image analysis software today. Many people consider this to be a sinister technology, with various use cases in surveillance and intelligence gathering. The time when you can say “big brother is watching you” is here.
However, most of the actionable applications of facial recognition software are beyond the Orwellian dystopia that most people associate them with. Ironically, many of them are being developed to protect us from intruders. For example, access control is one of the most prevalent uses of facial recognition. If you’re unlocking your smartphone by just looking at it, then you understand the convenience of such a technology. Pretty soon you may even be able to withdraw cash from an ATM by simply allowing it to recognize you.
At the same time, there are far more practical applications that extend to other domains. For example, the Russian Rambler Group is using facial recognition algorithm to better target in-theater ads. Expedia also has been experimenting with facial recognition for a while now trying to identify travel locations that evoke the most positive emotions.
Whatever your potential application of facial recognition algorithm might be, it’s important to understand the complexity of the technology to make the right call. You don’t want to waste your resources on a concept that’s not going to create real value for you and your business.
In essence, the technology is made possible through a plethora of mathematical algorithms that break down the images into pixels/data points and try to make sense of this newly acquired data through various manipulations.
Of course, this is a hugely simplified explanation. Facial recognition algorithms are varied in robustness and applications. Each of them has their advantages and disadvantages, as well as a variety of data pre-processing steps. Facial recognition on your smartphone works differently from facial recognition in street cameras. Some algorithms work better with a small pool of images, while others require a wide variety to perform well.
Let's talk about some of the basics of how facial recognition works, what are some of the significant problems in facial recognition, how a facial recognition pipeline works, and what are some of the latest innovations in this domain.
 Tweet
Tweet
Face Recognition is the Last Step
For facial recognition software to identify unique facial features, it has to perform a number of tasks. There are numerous definitions for facial recognition systems and what they encompass, but it all mostly boils down to the following stages:
- Face detection: first, the system has to identify the part of the image or the video that represents the face.
- Pre-processing: the data has to be transformed into a normalized, monolith format (the images have to be of the same resolution, levels of zoom, brightness, orientation, etc.). It is also often referred to as feature normalization.
- Feature extraction: the system has to extract meaningful data from the facial images, identifying the most relevant bits of data and ignoring all of the “noise.” It’s also referred to as encoding.
- Face recognition: the actual process of matching unique data features to each individual. The underlying principle here is called object classification.
This is a very simplified version of a face recognition system that uses algorithms to perform all of these transformations. Each of these steps includes additional processes. You’ll also be working with a few algorithms in conjunction. For example, the face detection stage alone uses a separate algorithm to identify facial features.
During all of these manipulations, there are various problems inherent to the type of data used (images, video), which are also not easy to overcome. These problems often shape the workflow for facial recognition and all of the various face detection/preprocessing/normalization steps involved. We’ll list some of these problems below.
- Illumination: the differences in lighting can affect recognition efficiency.
- Pose: the exact pose the person is taking during image capture.
- Age: facial features change over time, especially since certain parts of our faces keep growing throughout our lifetimes.
- Occlusion: partially covered up facial features can negatively affect the recognition process – sunglasses, hairstyles that partially conceal facial features, facial hair, cosmetics, etc.
- Resolution: if images are taken from various sources and normalized, it’s likely that you’ll have to change resolutions for some of them, which will negatively affect their quality.
To deal with all of these issues, a specific facial recognition pipeline might employ a few algorithms and techniques to normalize the data and improve recognition capabilities.
There are numerous face recognition algorithms. Some of them are older; some are newer. It’s important to note that their efficiency will also depend on the types of data/images that you will be working with. Let’s take a brief look at a couple of them.
PCA - Principal Component Analysis
Principal components are the underlying structures in the data. They represent directions where the data is the most spread out. This algorithm performs dimensionality reduction (“compressing” data into its principal components). In the 1980s an effective facial recognition framework based on PCA has been developed, called Eigenfaces. It is still being used for various facial recognition problems. Don’t be scared. This is how PCA "sees" your face.

BP - Local Binary Pattern
Local Binary Pattern is a texture operator which labels the pixels of an image by thresholding the neighborhood of each pixel and considers the result as a binary number (1 or 0). It is relatively easy to compute, but it has proven to be very effective at encoding facial features. Each face image can be considered as a composition of micro-patterns compiled from each binary-based representation of the pixel, which can be effectively detected by the LBP.

A plethora of other algorithms work with facial recognition (ICA, EBGM, Kernel Methods, etc.). Some of them may already be obsolete for your specific facial recognition problem, but many are still actively used in various interpretations. Legacy algorithms have their merits, but with the explosive growth of computing capacity, they often lose to more advanced approaches.
Tweet
Neural Networks, Deep Learning, and Other Buzzwords
By now, you should understand the basic workflow of a facial recognition system and some of its challenges. This is where it gets tricky. Some of the described above steps and algorithms may already be obsolete or completely useless compared to the innovations that drive the more advanced facial recognition technologies.
Machine learning is ruling the facial recognition game. But there’s a subset of machine learning algorithms, which takes the cake when it comes to recognizing faces. They fall under deep learning and are called neural networks.
Their architectures are varied and complicated, and, often, we can’t even decipher the results of their calculations or even the values that they output. In one example, when an image is run through a neural network, it reliably outputs a set of measurements that serve as a unique identifier of that face. These sets of measurements are called embeddings. And we don’t even know what those 128 points measure on a face.
We don’t exactly care how our brain works when we recognize a familiar face. The same principle applies here. This network can generate nearly identical embeddings for images of the same person, which can later be compared to identify the person. And this is all that matters.
Convolutional neural networks are a subtype in this category, and they prove to be pretty effective. They also require minimal preprocessing of data. And this is one of the reasons why they’re widely adopted for image-recognition problems.

But apart from being more “convenient” for facial recognition problems, neural networks have also proven to be more effective at the task than standard algorithms or even their combinations. The recent research by the Faculty of Electrical Engineering at the University of Zilina shows a CNN outperforming PCA, KNN, and other algorithms by at least 10%-15% in accuracy.
Another research by a multi-national panel of computer scientists from Asia shows that an advanced CNN outperforms the majority of widely adopted algorithms, achieving almost a 100% accuracy (99.8% in one of the experiments). The mounting evidence proves that neural networks, on average, are superior to their “hand-made” counterparts. That’s why major tech companies have been using neural networks for this task for a while. Like in the case of Apple, which started using deep learning for face recognition on iOS 10.
Now that we know a bit more about the broader scope of technologies used in facial recognition let’s take a look at a theoretical workflow for a facial recognition application.
Tweet
Step by Step Facial Recognition
Please note that this is just one approach that we’re showing as an example. There are more elegant ways of doing face recognition, especially given that various tools for this task are becoming more accessible (we’ll talk about them later on). We wanted to showcase some of the complexity that might be involved in a facial recognition project.
Let’s assume that you already have image data coming in and you need to start recognizing faces. The initial step, as we previously described, would be to start detecting faces.
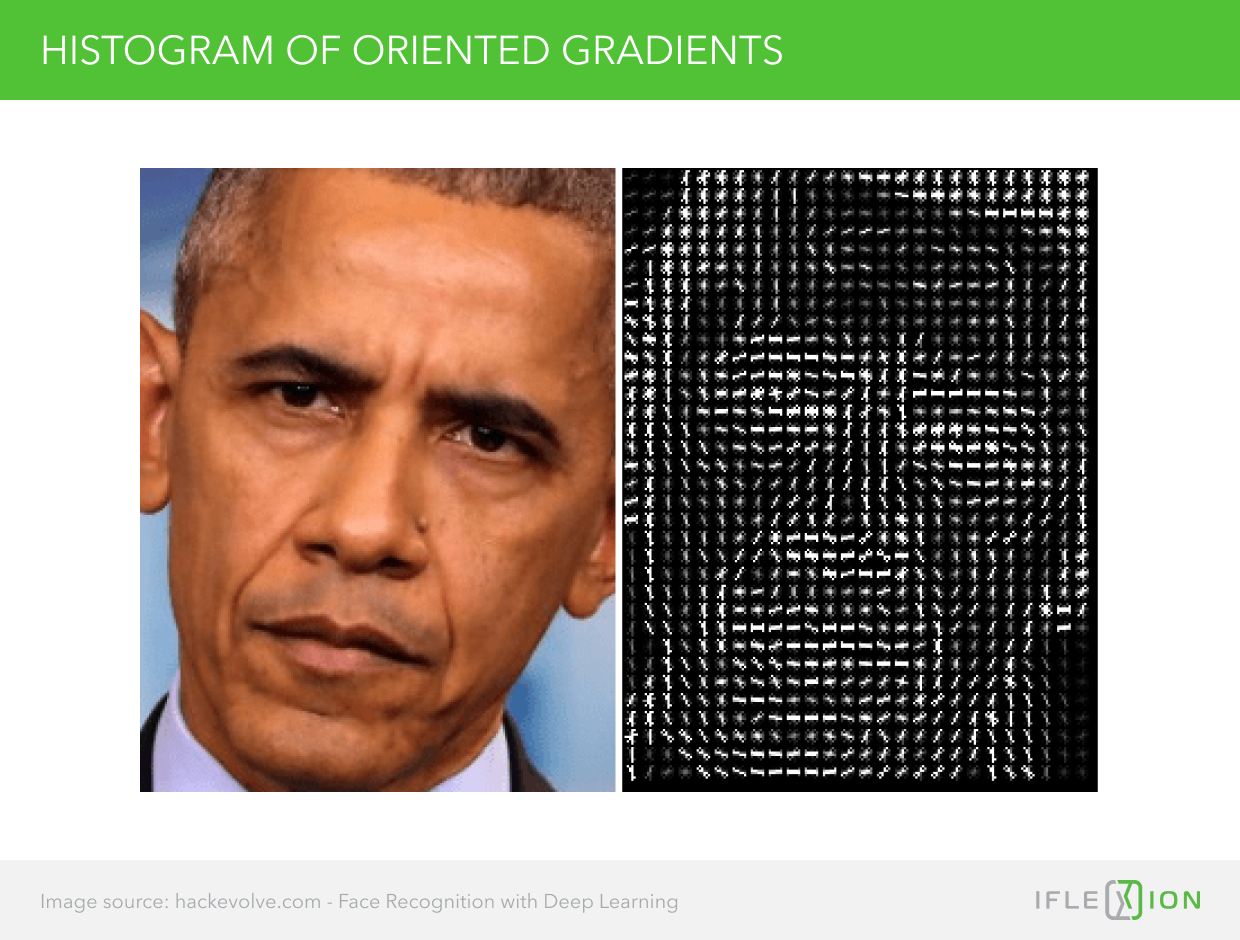
There are many options for this step, but we’re going to be using one of the more common ones – Histogram of Oriented Gradients (HOGs):
- We take an image and convert it into black and white, as face detection doesn’t require color.
- Every pixel in the image is analyzed in conjunction with its neighboring pixels. Each pixel is substituted with a vector that moves toward the part of the image that’s getting darker. These vectors are referred to as gradients. Why are we doing this?
If we analyzed just the different colors in pixels, we’d end up with different values for images of the same person, since the color depends on the way the photo is taken, the lighting and so on. The direction of the change in brightness of facial features is a much better representation. A very “dumb” but good example would be your nose. It will cast a shadow, and it doesn’t matter which direction the light source is coming from – the vectors will still point towards the nose (as the shadow is the darkest right next to it), creating a landmark of sorts.
3. Now we need to simplify it, so the data would not create too much noise, making it hard to identify the overall pattern. We need to “move” these gradients to a higher level. For this, we’ll break down the images into squares. Count up the number of gradients in those squares and assign the direction that was most frequent to the whole square.
4. This is an example of what you’d get (original vs. HOG representation).
5. Then you’ll need to compare your image to other previously extracted faces (training data). The part that will look most similar to the training data will be the detected face.
Now that we can detect faces, we need to be able to normalize the images to account for the various poses. First, we need to find facial landmarks and center the image around them.
6. Come up with facial landmarks.
7. Train an ML algorithm so it could recognize these landmarks.
8. Perform transformations on your images, so that the underlying facial features would always line up with the landmark template that we created earlier. You can achieve this with affine transformations, which don’t distort the face and preserve its features that run in parallel. Of course, you could skip the hustle of training a model for landmark detection and use some of the already available code. There are also tons of great tutorials and GitHub repos for affine transformations.
By now we can detect a face and normalize it so that it would be presented in the same way. Now is the time to start recognizing faces. For this, we’ll be encoding faces using a CNN (convolutional neural network), so that each unique face would be presented by a set of unique identifiers (those 128 embeddings that we mentioned earlier in the article).
9. The training process is very complicated and can be performed in various ways. But there’s already a solution – the OpenFace project did all of the heavy liftings, and they have a script that can generate embeddings for given images and output them in a file.

At this point, you have a workflow that generates embeddings for every picture that’s run through it: the face is detected – its features are normalized through affine transformations – these transformed faces are then fed into a CNN that outputs embeddings. Now we can start recognizing people. For this, we need to train a classification ML algorithm that can find images with similar measurements/embeddings. The algorithm essentially puts each picture in a bucket, where each bucket represents a single person.
10. This could be done through an SVM (support vector machine) or other suitable classification algorithms. Once we’ve trained the algorithm, it can reliably recognize the person.
This is a very simplistic representation of an actual workflow and all of the laborious steps that it incorporates. But we hope that you now have the idea of how it all comes together. There are plenty of pre-packaged projects and open-source code that can help you do many of these steps.
An Afterthought
Facial recognition is still a novel technology. A lot of the work done in the field is experimental. Pretty often, you’ll see people just trying to improve on the methods that they saw in an academic publication with hopes of improving the accuracy and speed of the process. That’s why even big companies suffer from failures in facial recognition algorithm. For example, a recent MIT study showed that Microsoft’s facial recognition technology had a bias towards women with darker skin tones, resulting in an over 20% error rate. Microsoft has taken steps to alleviate these issues since then.
That’s another reason why tech companies are investing in facial recognition and are publicly supporting R&D in this domain. For example, IBM recently released a huge image-based dataset that can be used for training machine learning algorithms/neural networks to better tackle facial recognition problems. Lack of good training datasets is somewhat of an issue for the technology, and that’s why biases, like that in Microsoft’s case, keep revealing themselves.
Tweet





WANT TO START A PROJECT?
It’s simple!